Preparate
Lifestyle requirements for our professional data science success.
Prepárate
TLDR
- We want a life with long-term financial security and short-term financial freedoms.
- Working as a data scientist can meet both of these desires.
- However, this path is fraught with macro-economic, industry-wide, and personal difficulties.
- Succeeding in-spite of existing challenges will likely require accepting unpleasant social constraints.
- Moreover, we’ll likely need “intense” time uses and planning.
Overview
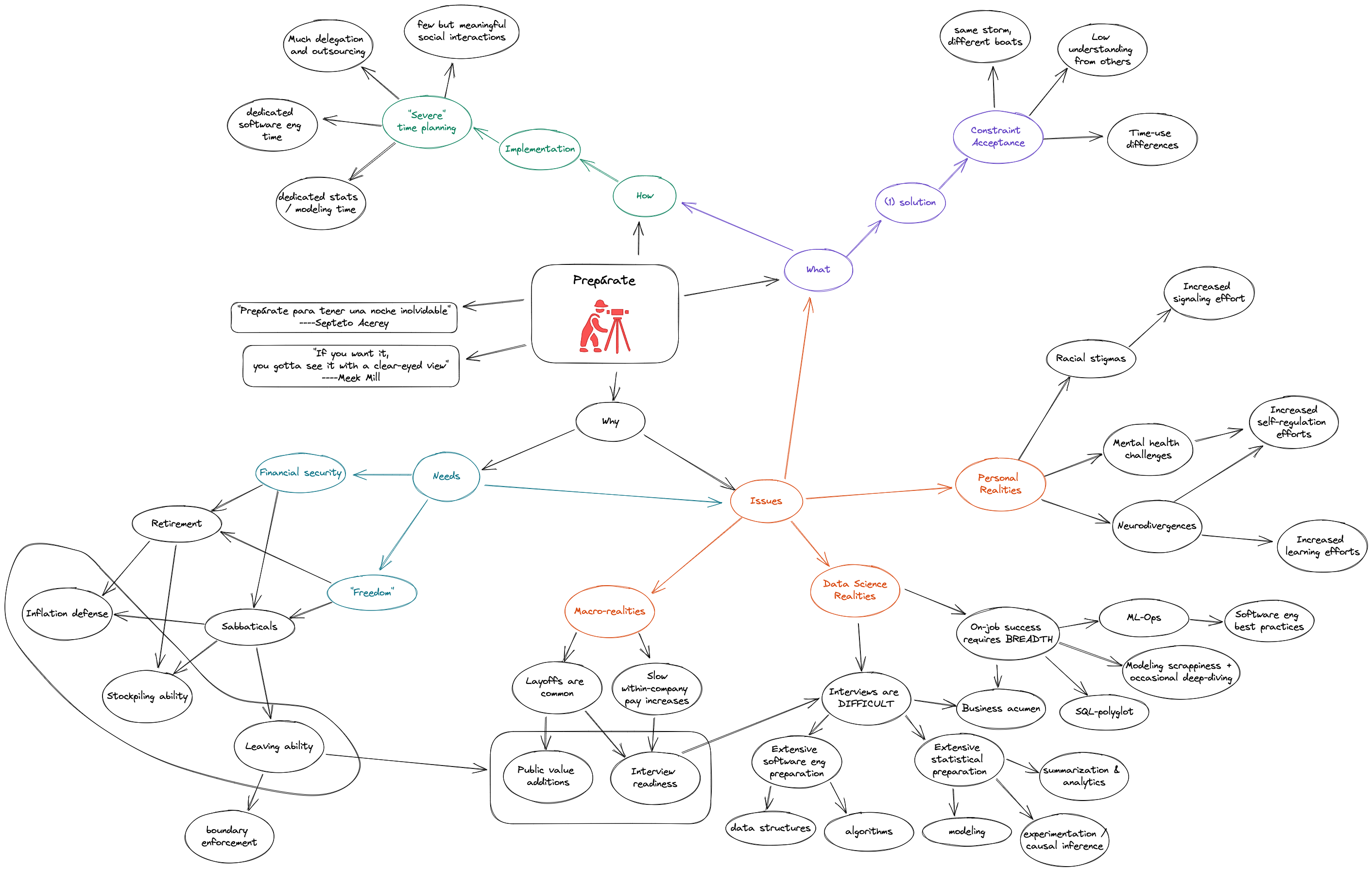
Needs
I used to pray for times like this, to rhyme like this.
So I had to grind like that to shine like this . […]
Seen my dreams unfold, nightmares come true,
it was time to marry the game and I said, “Yeah, I do.”
If you want it, you gotta see it with a clear-eyed view.
—Meek Mill, Dreams and Nightmares
Dear Young Tim,
Merry Christmas! More than ever, it’s clear that the best presents we can give ourselves are to meet our needs. Two such needs stand out as greatly important:
- assuring long-term financial security
- and providing for short-term financial freedoms.
Similar to many others, we want to retire in the future, while being secure in our ability to comfortably support ourselves. Likewise, we want the freedom to comfortably take shorter term sabbaticals. Such breaks help us recover from unexpected hardships or prepare for upcoming efforts.
In order to take sabbaticals or retire, we find that we require overlapping and non-trivial resources. For instance, we need to be able to stockpile investments that can support us while not employed. Further we require investments (financial or otherwise) that are able to resist inflation or depreciation. That is, our investments need to retain their usefulness over time. Finally, we need the ability to leave (and return). While less of an issue for final departures in retirement, we are unlikely to take sabbaticals if we cannot return to employment afterwards. And to be clear, without the ability to leave and later return, it will be hard to enforce boundaries that protect our quality of life while working.
On the surface, working in the field of data science seems to meet these lower-level requirements. One is paid relatively well, and thus able to stockpile resources. Many tech companies also offer stock-based compensation. If wisely managed, such compensation can resist inflation and appreciate over time. Finally, demand for data scientists is currently higher than supply. This surplus of opportunities eases the task of returning after a sabbatical.
However, like any engineer planning to build a complex system, we will benefit from carefully surveying the grounds we are about to begin working in. By identifying difficulties and problems before we begin (again), we can better prepare ourselves to avoid or cope with these issues.

Macro-realities
Let’s start by working from the outermost context inwards. We’ll consider the private sector because it has more data science positions (and higher pay) as compared to the public sector.
Within private corporations, pay increases are often best accessed by changing jobs in a booming economy. Conversely, in economic downturns, private sector layoffs are common. For example, according to layoffs.fyi, technology companies have laid off more than 150,000 workers in 2022.
The net result of these trends is that, in both boom and bust economies, we must be ready to switch private sector jobs. Such job switching involves being ready for interviews, and it also means maintaining a profile of public value-additions1. Given the demand surplus described above, these practices ensure that we (and our demonstrated value) are not wholly bound to a single employer. I.e., these practices provide the leaving ability we desire from “short-term financial freedom.”
Industry-realities
As noted above, we want to maintain readiness for data science interviews. Immediately, we’re led to consider the question of “how to maintain readiness?” Or more specifically, “what do we need to know, in order to be ready for data science interviews and work?” This question brings our attention one contextual level deeper, from private corporations in general to data science in particular. We’ll look at the realities of both interviewing to get data scientist positions and performing once in the role.
Interviewing
The first thing to note about data science interviews is that they are CHALLENGING. Their difficulty stems both from their depth and their breadth. In particular, data science interviews require extensive preparation in software engineering and in statistics. This level of preparation is typically far beyond what we learn in any one graduate program of study.
In software engineering, we’ll want to be intimately familiar with
- data structures,
- algorithms,
- computational complexity,
- graph traversal,
- search,
- sorting,
- dynamic programming,
- software testing,
- and industry tools for “big data” handling.
This familiarity includes both explicit knowledge as in “what is this” and tacit knowledge as in having much experience in “how, why, and when to use this.” Such levels of familiarity demand study and practice, especially since computer science wasn’t our primary area of study in school. Indeed, this software engineering focus for data scientists has been noted by many others: e.g., by statistician Yuling Yao and by modeler Phillip Price.
Similarly, in statistics, we’ll want to be intimately familiar with
- probability,
- summarization and analytics,
- experimentation and causal inference,
- and modeling, estimation, and assessment.
As with software engineering, we will be expected to be fluent in the details and use of all areas above. This means being ready to write code and math for all the above. In school, we touched each of these statistical topics, in serial. We also delved deeply into a subset of these topics simultaneously. The difficulty of interviews is to internalize and make this combined breadth and depth of knowledge available all at once.
Finally, we’ll also need to be aware of the business terminology and concerns for each company we’re interviewing with. Though terminology and specific concerns will change with each company’s domain, interviews will test a basic understanding of business fundamentals.
Performing
When considering on the job performance, we face a parallel situation to interview preparation. The core difference is that breadth is more important day-to-day, whereas depth is only needed infrequently.
For example, business acumen is of regular use, due to frequent meetings with cross-functional partners: product managers, engineers, designers, business teams, etc. In such meetings, statistical details are rarely the focus of discussion.
Moreover, even when doing solo work, most of our time may be spent gathering data or building and maintaining pipelines for models in production. Here, we’ll need to be something of a SQL polyglot and an ML-Ops master, simply due to job necessity. This focus brings a demand for software engineering best practices that is unlikely to be assessed thoroughly in interviews but is of great importance for easing our life in practice. E.g. tons of data and software testing to prevent or catch errors. Time will need to be spent learning these skills as well.
Finally, there will be immense demand for development speed. As our time is money (a “downside” to high pay), businesses rarely allow the long-term efforts common in academia. Moreover, most ideas fail in experiment. There are many reasons for this, but the outcome for businesses is a preference to “fail fast” and therefore work fast as well. Highly original model development or sophisticated experiment design and analysis will therefore be a professional exception, not the norm. We’ll want to maintain agility with the basics of many techniques, and the ability to go deeper when necessary, rather than only maintaining depth of knowledge in a few areas.
Personal-realities
As detailed in the previous sections, there is much to be learned to prepare for data science interviews and work. In all honesty, the mountain of subjects concerns and intimidates us. It is helpful here, to consider the final contextual level—ourselves. What about our current position in life will complicate our efforts?
To start, we have decades of experience and professional corroboration that we learn differently than our peers. Not less well in outcome, but differently in process. Indeed, neurodivergence is a thing. We require much more repetition than many others, and we require an atypically wide range of learning efforts. All of this translates to increased efforts to gain proficiency with an already ambitious number of topics.
Moreover, we approach this technical learning with challenging mental health circumstances. These challenges necessitate our increased efforts in emotional regulation. Of course, nothing is really free, so the increased time spent on emotional regulation efforts means less time available for other activities, such as learning and studying. Combined with the previous paragraph, we see that we need to do more learning activities with fewer time resources than if “all was well.”
Finally, there is my typically unstated skin in the game. By that, I mean the ramifications of being black. At every company I’ve worked at as a data scientist, I was always the first (or only) black data scientist. We can endlessly discuss the reasons for this, but nonetheless, these realities motivate us toward “constant vigilance.” We have a felt sense that we must work extra hard to get a seat at any table we want to eat at. Such extra efforts exacerbate the issue of needing to learn more with less time.
For example, distinguished engineer2 Kelsey Hightower notes that:
growing up, I was always taught I got to be twice as good.
That’s a real thing for those that don’t know, right.
Your parents tell you, you got to be twice as good.
What they were trying to get me to understand,
I believe, is I had to hedge against all the hidden obstacles.
—24:40 to 25:00
My parents, like many other black parents in the United States, always said the same thing. To be clear, such instructions are hyperbole. There are many people producing a ton of great work, e.g. Sayak, Dr. Kozodoi, and lots more. It is therefore difficult to specify what twice as good looks like, much less how to produce it on a budget of 168 hours per week. The underlying encouragement, to paraphrase computer science professor Cal Newport, is to be “so good they can’t ignore you” while accounting for additional hurdles from (unconscious) bias.
Constraint acceptance
Above, we provide a multi-layered view of expected challenges to pursuing a career in data science. What can we do about them? The first thing we can do is accept that coping with these challenges imposes constraints on our life. In particular, there are multiple such social constraints.
First, our aforementioned industry and personal realities will necessitate that we use our time differently from most of our existing friends and family. We will need to allocate many hours to “extra-curricular” studying, far more than typically expected after one earns a PhD. We will be less available than otherwise expected or wished. To help maintain morale, we will benefit from clearly noting exactly why we’re signing up for such a monastic lifestyle. This will be particularly helpful when we encounter unexpected technical difficulties alone.
Second, beyond living quite differently than others, most of our support network is unlikely to understand why we choose to live so differently. Indeed, as shown by the length of this post, the reasons are not singular. There is a tapestry of contributing factors, operating at multiple levels. Expectedly, few people will have time to make sense of it all.
Consider Hightower’s experience once more. He said
so I spent, I don’t know, four to five hours
every day when I got home.
I was like ‘yo, what else can I learn?’
[…]
So my hustle, my hustle was unbelievable.
A lot of people couldn’t understand
why I took this game so serious…
and I tried to explain.
Like, I remember when, you know,
a lot of people decided that sports entertainment
was going to be their way out the hood.
I looked at tech skills as a similar route.
Like, if you learn these skills,
you might get to a situation
where it’s going to be hard to deny your talent.
—14:35 to 14:41 and 30:05 to 30:32
With such extreme time investments, we may be (and we have been) characterized as uncaring or as a workaholic. So, even more than usual, we’ll need to make peace with being misunderstood— especially while we lack anything like Hightower’s success to redeem our efforts.
Lastly, we can expect collaborations to be short lived, if they occur at all. In April 2020, writer Damian Barr noted that “we are not all in the same boat. We are in the same storm.” This is true even when considering other data scientists. It was true even in graduate school when we worked in a research group. Though subjected to similar macro-level and industry realities, other data scientists will operate from different personal realities.
Some will have differing professional focuses, such as greater within-company focus. Some will have far greater non-technical focus, such as on their hobbies, friends, and families (especially if they are parents). Still others will have different technical focuses. E.g., some will focus on modeling with little engineering regard, and others will focus on engineering with little modeling regard. And so, for many possible reasons, we can expect our relationships with other technical workers to also be quite limited.
Severe planning
Given the challenges and constraints noted above, we are still left wondering, what can we proactively do to set ourselves up for data science success?
Here are a few steps we can take.
First, noting that time is our greatest constraint, we can explicitly plan to outsource as many tasks as possible. On what cadence can we order food or purchase ready-made meals to save preparation and clean-up time? On what cadence can we hire others to wash, dry, and fold our laundry? On what cadence can we have others clean our home? How much time can we afford to recoup in exchange for money?
Second, we can be more intentional with our social interactions. Given that time will be limited, exactly how much time will we allocate to socializing per week or per month? With whom do we want to interact and on what ideal cadence? How much and how frequently will we allocate time for meeting new people or serendipitous interactions? How will we make the most of our time with others?
Lastly, we will also want to be intentional about our study time. Exactly how much time, and when, will we study software engineering? How much time, and when, will we study statistics? When and how much will we work on open-source and research projects? What time will we devote to studying business? To the extent that we hope to learn what’s needed for interviews and on-the-job success, we’ll benefit from creating explicit study plans and schedules.
Related
With our suggestions for data science success and our survey of expected problems in the field, today’s post relates to numerous past writings. As has been our Christmas tradition, we again turn our focus to how we can “do data science.”
For Christmas 2020, in Do-Over, we spoke of how we’d go through school differently to prepare for a career in data science. That post focused mostly on recommendations for how we do our technical work. Today’s post is directly related, as it is also about preparing for a career in data science. This relation is shown in our map of blog content, below, with today’s post in highlighted in blue. Where our current writing differs from “Do-Over” is by focusing more on what technical work is required and how we can make space in our life to do it.
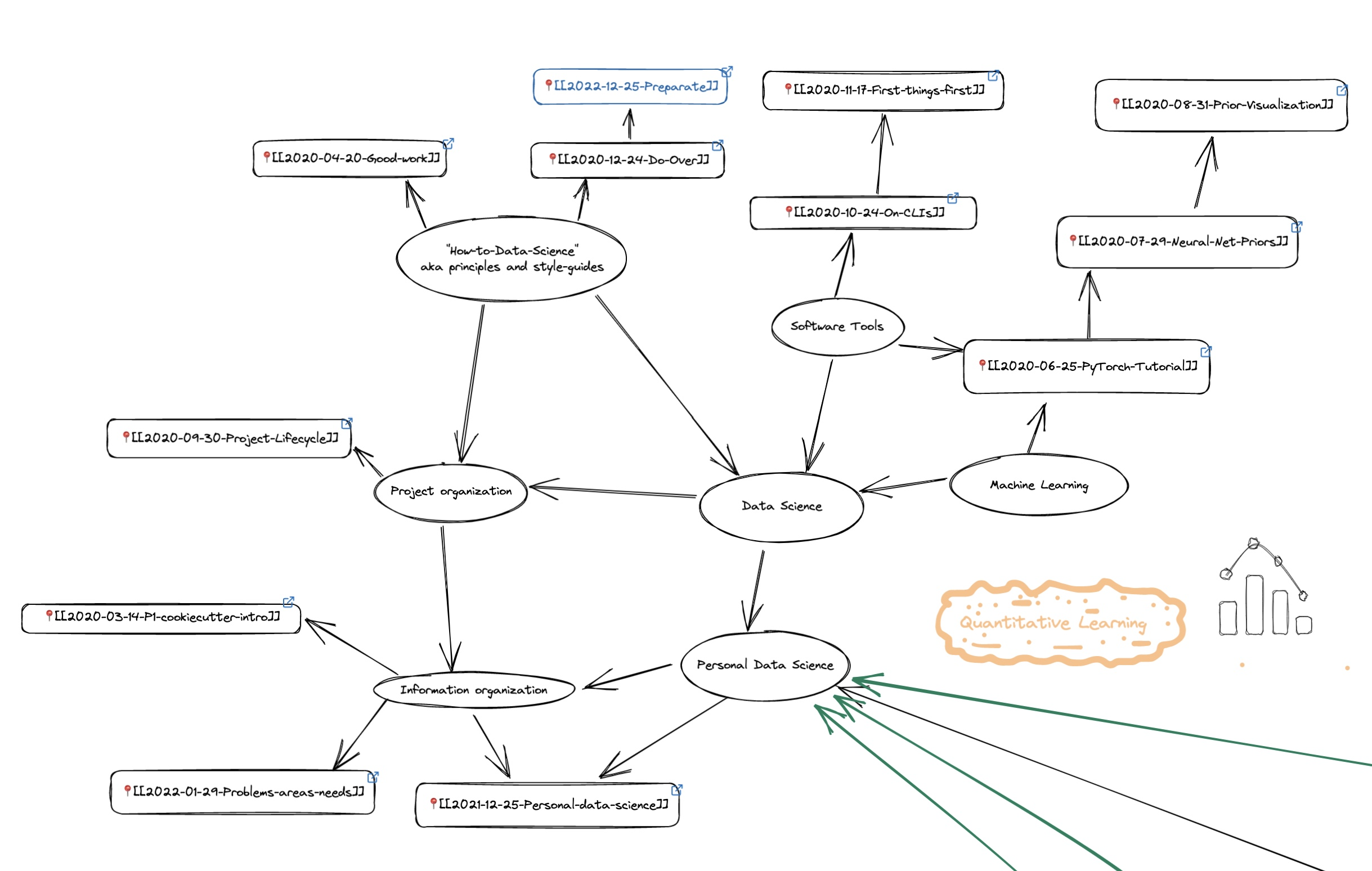
For Christmas 2021, in Personal Data Science, we turned our attention to questions of where to focus our data science efforts. What meaningful applications could we bring a data science lens to? “Personal Data Science” notably reminds us that our emotional regulation efforts can be beneficially combined with our data science practice. We need not see the two efforts as only adversarial.
For Christmas 2022, we look broadly at lifestyle decisions we can make to support our data science efforts. Ultimately, we want to produce Good Work in data science. This quality of work requires an advanced mix of engineering, statistical, and business capabilities. Today’s post focuses on how we can prepare ourselves for the studies and practice needed to gain those skills.
Adelante
In closing, Young Tim, I hope the words above clarify some of the expected hardships in data science and some ways to work around them. What I wish I told you earlier was to rest easy through 2022 and through its close.
Y Timo, no tengas miedo.
Prepárate, porque en 2023—nos trabajamos.
De verdad:
Prepárate
para tener
una noche inolvidable.
De las que no quieres que acaben.
Una noche inolvidable,
de las que no quieres que acaben.
—Septeto Acerey, Esta Noche Pinta Bien